2011-06-08 by Stefan Urbanek
undefined
undefined
undefined
New way of constructing streams has been implemented which uses “higher order messaging”. What does that mean? Instead of constructing the stream from nodes and connections, you “call” functions that process your data. You pretend in your script that you work with data using functions:
...
main.csv_source("data.csv")
main.sample(1000)
main.aggregate(keys = ["year"])
main.formatted_printer()
...
Executing the functions as written in a script might be be very expensive from time and memory perspective. What is in fact happening is that instead of executing the data processing functions a stream network is being constructed.
Construction is being done by using forked branches. You create an empty forked branch by forking an empty stream:
from brewery.streams import * stream = Stream() main = stream.fork() ...
Now you have fork main. Each function call on main will append new processing node to the fork and the new node will be connected to the previous node of the fork.
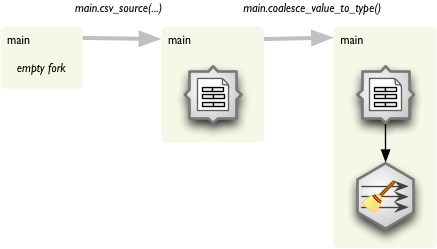
Function names are based on node names in most of the cases. There might be custom function names for some nodes in the future, but now there is just simple rule:
CSVSourceNode to csv source nodecsv_source_nodecsv_sourceArguments to the function are the same as arguments for node constructor. If you want to do more node configuration you can access current node with node attribute of the fork:
main.node.keys = ["country"]
Run the stream as if it was constructed manually from nodes and connections:
stream.run()
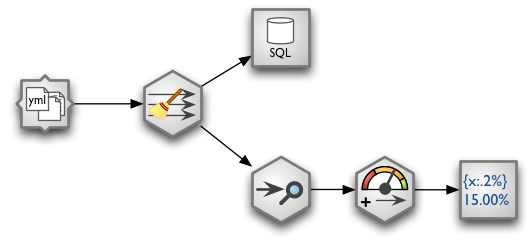
So far you are able to construct single simple stream from a source to a target. There are plenty of situations where linear processing is not sufficient and you will need to have branches. To create another branch, you fork() a fork. For example, to attach data audit to the stream insert following code right after the node you want to audit:
# we are in main at node after which we want to have multiple branches audit = main.fork() audit.audit() audit.value_threshold(...) audit.formatted_printer(...) # continue main.* branch here...
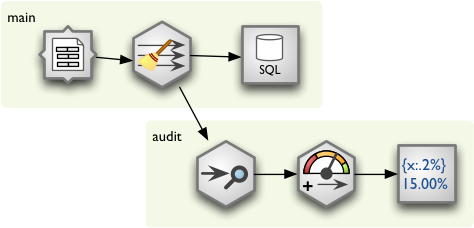
Here is full example how to use forking with HOM in Brewery:
# Create the stream and empty fork
stream = Stream()
main = stream.fork()
# Start adding nodes by pretending that we are processing using functions
main.csv_source("data.csv", read_header = True, encoding = "utf-8")
main.coalesce_value_to_type()
# Create another fork for data audit:
audit = main.fork()
audit.audit(distinct_threshold = None)
audit.value_threshold(thresholds = [ ["null_record_ratio", 0.01] ],
bin_names = ("ok", "fail"))
audit.formatted_printer()
audit.node.header = u"field nulls status distinct\n" \
"------------------------------------------------------------"
audit.node.format = u"{field_name:7.2%} {null_record_ratio_bin:>10} {distinct_count:>10}"
# ...and we continue in main branch
main.database_table_target(url = "postgres://localhost/sandbox",
table = "data",
create = True,
replace = True,
add_id_key = True)
# Run the stream and pretty-print the exception
try:
stream.run()
except pipes.StreamRuntimeError, e:
e.print_exception()
The constructed stream looks like this:
New subproject sprouted in Brewery: Opendata. The new package will contain wrappers for various open data services with APIs for structured data. First wrapper is for the Scraper Wiki. There are two new classes: ScraperWikiDataSource for plain data reading and ScraperWikiSourceNode for stream processing.
Example with ScraperWikiDataSource: Copy data from Scraper Wiki source into a local database. Table will be automatically created and replaced according to data structure in the source:
from brewery.opendata import *
from brewery.ds import *
src = ScraperWikiDataSource("seznam_insolvencnich_spravcu")
target = SQLDataTarget(url = "postgres://localhost/sandbox", table = "swiki_data",
create = True, replace = True)
src.initialize()
target.fields = src.fields
target.initialize()
for row in src.rows():
target.append(row)
src.finalize()
target.finalize()
Another example using streams: simple completeness audit report of source data. Fail threshold is set to 10%.
The stream looks like this:
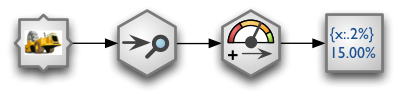
And the source code for the stream set-up is:
nodes = {
"source": ScraperWikiSourceNode("seznam_insolvencnich_spravcu"),
"audit": AuditNode(distinct_threshold = None),
"threshold": ValueThresholdNode(),
"print": FormattedPrinterNode(),
}
connections = [
("source", "audit"),
("audit", "threshold"),
("threshold", "print")
]
nodes["print"].header = u"field nulls status distinct\n" \
"------------------------------------------------------------"
nodes["print"].format = u"{field_name:<30.30} {null_record_ratio: >7.2%} {null_record_ratio_bin:>10} {distinct_count:>10}"
nodes["threshold"].thresholds = [ ["null_record_ratio", 0.10] ]
nodes["threshold"].bin_names = ("ok", "fail")
stream = Stream(nodes, connections)
try:
stream.run()
except StreamRuntimeError, e:
e.print_exception()
Output:
field nulls status distinct ------------------------------------------------------------ cp_S 0.00% ok 84 cp_TP 31.00% fail 66 datumNarozeni 18.00% fail 83 denPozastaveni 100.00% fail 1 denVzniku 0.00% ok 91 denZaniku 100.00% fail 1 dne 99.00% fail 2 dobaPlatnosti 100.00% fail 1 ... nazev 82.00% fail 19 okres_S 5.00% ok 38 okres_TP 38.00% fail 35 ...
In this example you can see how successful you scraper is or how complete the provided data are. This simple stream helps you to fine-tune your scraping method.
Possible use, besides during development, would be to integrate the stream into automated process to get feedback on how complete your daily/monthly processing was.
In one of the following posts I will show you how to do “join” (in SQL sense) between datasets, for example how to enrich data from Scraper Wiki with details you have stored in a CSV or another scraper.
Freshly brewed clean data with analytical taste – that is what Data Brewery is for. The Python framework will allow you to:
You can use Brewery for analytical automation or just for ad-hoc analytical processing.
Project page is at databrewery.org. Source repository can be found at:
Documentation with examples and node reference can be found here.
Happy brewing!