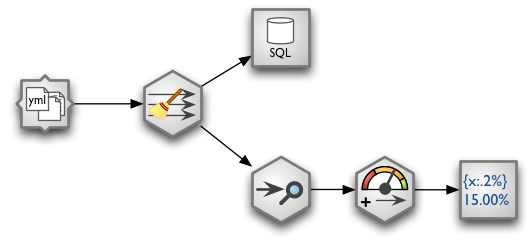
Brew data from Scraper Wiki
New subproject sprouted in Brewery: Opendata. The new package will contain wrappers for various open data services with APIs for structured data. First wrapper is for the Scraper Wiki. There are two new classes: ScraperWikiDataSource for plain data reading and ScraperWikiSourceNode for stream processing.
Example with ScraperWikiDataSource: Copy data from Scraper Wiki source into a local database. Table will be automatically created and replaced according to data structure in the source:
from brewery.opendata import *
from brewery.ds import *
src = ScraperWikiDataSource("seznam_insolvencnich_spravcu")
target = SQLDataTarget(url = "postgres://localhost/sandbox", table = "swiki_data",
create = True, replace = True)
src.initialize()
target.fields = src.fields
target.initialize()
for row in src.rows():
target.append(row)
src.finalize()
target.finalize()
Another example using streams: simple completeness audit report of source data. Fail threshold is set to 10%.
The stream looks like this:
- from scraper wiki feed data to data audit node
- based on value threshold generate new textual field that will state whether the data passed or failed completeness test (there should be no more than 10% of empty values)
- print formatted report
And the source code for the stream set-up is:
nodes = {
"source": ScraperWikiSourceNode("seznam_insolvencnich_spravcu"),
"audit": AuditNode(distinct_threshold = None),
"threshold": ValueThresholdNode(),
"print": FormattedPrinterNode(),
}
connections = [
("source", "audit"),
("audit", "threshold"),
("threshold", "print")
]
nodes["print"].header = u"field nulls status distinct\n" \
"------------------------------------------------------------"
nodes["print"].format = u"{field_name:<30.30} {null_record_ratio: >7.2%} {null_record_ratio_bin:>10} {distinct_count:>10}"
nodes["threshold"].thresholds = [ ["null_record_ratio", 0.10] ]
nodes["threshold"].bin_names = ("ok", "fail")
stream = Stream(nodes, connections)
try:
stream.run()
except StreamRuntimeError, e:
e.print_exception()
Output:
field nulls status distinct ------------------------------------------------------------ cp_S 0.00% ok 84 cp_TP 31.00% fail 66 datumNarozeni 18.00% fail 83 denPozastaveni 100.00% fail 1 denVzniku 0.00% ok 91 denZaniku 100.00% fail 1 dne 99.00% fail 2 dobaPlatnosti 100.00% fail 1 ... nazev 82.00% fail 19 okres_S 5.00% ok 38 okres_TP 38.00% fail 35 ...
In this example you can see how successful you scraper is or how complete the provided data are. This simple stream helps you to fine-tune your scraping method.
Possible use, besides during development, would be to integrate the stream into automated process to get feedback on how complete your daily/monthly processing was.
In one of the following posts I will show you how to do “join” (in SQL sense) between datasets, for example how to enrich data from Scraper Wiki with details you have stored in a CSV or another scraper.