2011-09-29 by Stefan Urbanek
I am happy to announce another release of Cubes - Python OLAP framework for multidimensional data aggregation and browsing.
This release, besides some new features, renames Cuboid to more appropriate Cell. This introduces backward python API incompatibility.
Main source repository has changed to Github https://github.com/Stiivi/cubes
Changes
- Class ‘Cuboid’ was renamed to more correct ‘Cell’. ‘Cuboid’ is a part of cube with subset of dimensions.
- all APIs with ‘cuboid’ in their name/arguments were renamed to use ‘cell’ instead
- Changed initialization of model classes: Model, Cube, Dimension, Hierarchy, Level to be more “pythony”: instead of using initialization dictionary, each attribute is listed as parameter, rest is handled from variable list of key word arguments
- Improved handling of flat and detail-less dimensions (dimensions represented just by one attribute which is also a key)
Model Initialization Defaults:
- If no levels are specified during initialization, then dimension name is considered flat, with single attribute.
- If no hierarchy is specified and levels are specified, then default hierarchy will be created from order of levels
- If no levels are specified, then one level is created, with name
default and dimension will be considered flat
Note: This initialization defaults might be moved into a separate utility function/class that will populate incomplete model (see Issue #8 )
New features
Slicer server:
- changed to handle multiple cubes within model: you have to specify a cube for /aggregate, /facts,… in form: /cube//
- reflect change in configuration: removed
view, added view_prefix and view_suffix, the cube view name will be constructed by concatenating view prefix + cube name + view suffix
- in aggregate drill-down: explicit dimension can be specified with drilldown=dimension:level, such as:
date:month
This change is considered final and therefore we can mark it is as API version 1.
Links:
If you have any questions, comments, requests, do not hesitate to ask.
2011-06-25 by Stefan Urbanek
New small release is out with quite nice addition of documentation. It does not bring too many new features, but contains a refactoring towards better package structure, that breaks some compatibility.
Documentation updates
Framework Changes
- added soft (optional) dependencies on backend libraries. Exception with useful information will be raised when functionality that depends on missing package is used. Example: “Exception: Optional package ‘sqlalchemy’ is not installed. Please install the package from http://www.sqlalchemy.org/ to be able to use: SQL streams. Recommended version is > 0.7”
- field related classes and functions were moved from ‘ds’ module to ‘metadata’ and included in brewery top-level: Field, FieldList, expand_record, collapse_record
- added probes
Depreciated functions
Streams
- new node: DeriveNode - derive new field with callables or string formula (python expression)
- new SelectNode implementation: accepts callables or string with python code
- former SelectNode renamed to FunctionSelectNode
Enjoy!
Links
2011-06-08 by Stefan Urbanek
undefined
2011-04-25 by Stefan Urbanek
New version of Cubes - Python OLAP framework and server - was released.
Cubes is a framework for:
Notable changes:
- added ‘details’ to cube metadata - attributes that might contain fact details which are not relevant to aggregation, but might be interesting when displaying facts (such as contract name or notes)
- added ordering of facts in aggregation browser
SQL
- SQL denormalizer can now, by request, automatically add indexes to level key columns
- one detail table can be used more than once in SQL denomralizer (such as an organisation for both - supplier and requestor), added key
alias to joins in model description, see joins documentation for more information.
Slicer server
- added
log a and log_level configuration options (under [server])
- added
format= parameter to /facts, accepts json and csv
- added
fields= parameter to /facts - comma separated list of returned fields in CSV (see API)
- limit number of facts returned in JSON (configurable by
json_record_limit in [server] section), CSV can return whole dataset and will do it iteratively (we do not want to consume all of our memory, do we?)
Also many bugs were fixed, including localization in fact(s) retrieval and pagination. Sharing of single SQLAlchemy engine and model within server thread was added for performance reasons.
Enjoy.
2011-03-28 by Stefan Urbanek
New way of constructing streams has been implemented which uses “higher order messaging”. What does that mean? Instead of constructing the stream from nodes and connections, you “call” functions that process your data. You pretend in your script that you work with data using functions:
...
main.csv_source("data.csv")
main.sample(1000)
main.aggregate(keys = ["year"])
main.formatted_printer()
...
Executing the functions as written in a script might be be very expensive from time and memory perspective. What is in fact happening is that instead of executing the data processing functions a stream network is being constructed.
Construction
Construction is being done by using forked branches. You create an empty forked branch by forking an empty stream:
from brewery.streams import *
stream = Stream()
main = stream.fork()
...
Now you have fork main. Each function call on main will append new processing node to the fork and the new node will be connected to the previous node of the fork.
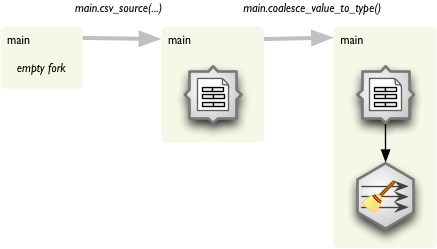
Function names are based on node names in most of the cases. There might be custom function names for some nodes in the future, but now there is just simple rule:
- decamelize node name:
CSVSourceNode to csv source node
- replace spaces with underscores:
csv_source_node
- remove ‘node’ suffix:
csv_source
Arguments to the function are the same as arguments for node constructor. If you want to do more node configuration you can access current node with node attribute of the fork:
main.node.keys = ["country"]
Running
Run the stream as if it was constructed manually from nodes and connections:
stream.run()
Forking
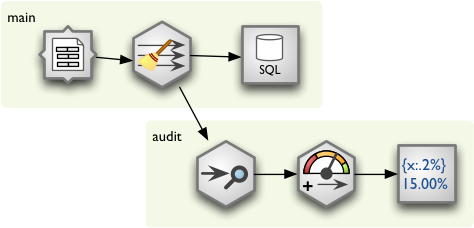
So far you are able to construct single simple stream from a source to a target. There are plenty of situations where linear processing is not sufficient and you will need to have branches. To create another branch, you fork() a fork. For example, to attach data audit to the stream insert following code right after the node you want to audit:
# we are in main at node after which we want to have multiple branches
audit = main.fork()
audit.audit()
audit.value_threshold(...)
audit.formatted_printer(...)
# continue main.* branch here...
Example
Here is full example how to use forking with HOM in Brewery:
# Create the stream and empty fork
stream = Stream()
main = stream.fork()
# Start adding nodes by pretending that we are processing using functions
main.csv_source("data.csv", read_header = True, encoding = "utf-8")
main.coalesce_value_to_type()
# Create another fork for data audit:
audit = main.fork()
audit.audit(distinct_threshold = None)
audit.value_threshold(thresholds = [ ["null_record_ratio", 0.01] ],
bin_names = ("ok", "fail"))
audit.formatted_printer()
audit.node.header = u"field nulls status distinct\n" \
"------------------------------------------------------------"
audit.node.format = u"{field_name:7.2%} {null_record_ratio_bin:>10} {distinct_count:>10}"
# ...and we continue in main branch
main.database_table_target(url = "postgres://localhost/sandbox",
table = "data",
create = True,
replace = True,
add_id_key = True)
# Run the stream and pretty-print the exception
try:
stream.run()
except pipes.StreamRuntimeError, e:
e.print_exception()
The constructed stream looks like this: